Update from OWS.EU partner projects: Part 1
In November 2023 OWS.EU successfully onboarded six new partner projects looking into technical, legal and economic research topics in support of the European Open Web Index that is currently in the making. The projects were selected in 2023 following an open call. Currently projects from the second and third calls are being reviewed with updates following soon.
Market potential assessment by Mücke Roth & Company
One of the endeavours from call #1 was the MRC project, dealing with economical questions related to an Open Web Index. The project was initiated by Mücke Roth & Company (MRC) with the goal to assess the market potential of OWS.EU.
The analysis is already fully executed, with a comprehensive study on the market potential of OWS.EU being the major result of the project. The study that has revealed substantial economic and societal benefits of OWS.EU will be presented to the public in autumn 2024.
Key achievements of the MRC work include a cost-benefit analysis, the identification of key customer segments and market dynamics through competitor benchmarking and a quantification of the European search engine market potential.
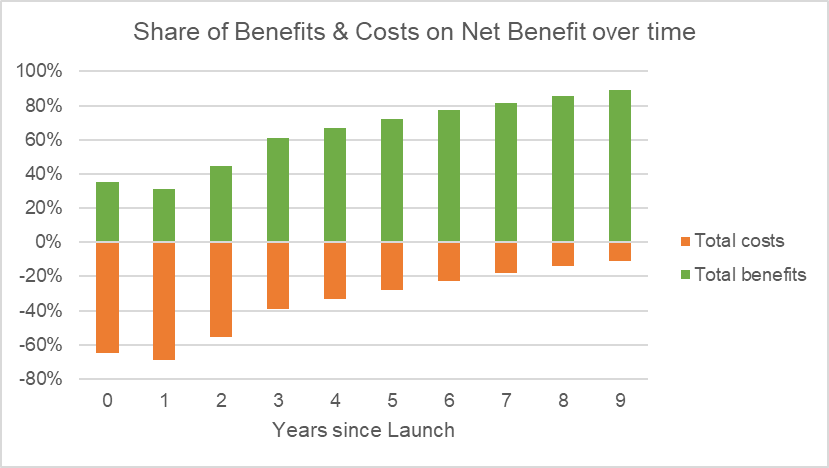
Figure 1: Share of Benefits & Costs on Net Benefit over time (Market Potential Assessment for OWS.EU by Mücke Roth & Company)
Last but not least, the assessment incorporates additional customer feedback and further interviews validating the findings of the MRC project. Strategic recommendations were provided to OWS.EU by the MRC team based on the results of their work.
Currently implications of the EU AI Act are monitored in order to adapt the strategy in case new regulations may arise.
Legal, Intellectual Property & Cyber Security Aspects of Open Web Search
The OWS.EU-Project raises a multitude of highly complex legal questions. LISA (Legal, Intellectual Property and Cyber-Security Aspects) is one of the legal projects that has taken the challenge to determine legal questions, identify relevant legal risks and adequately address them. The goal is to define a legal framework for the development and operation of an Open Web Search Index.
In the first half of the project, the team around Prof. Dr. Matthias Wendland from the University of Oldenburg defined what constitutes illegal content and established the legal duties for operators of an Open Web Index. Legal requirements for takedown requests, including those for criminal content, IP infringements, and data protection were set out. Additionally, the ownership of digital content and of the Open Web Index was clarified and the legal framework necessary for sharing the index was created. Furthermore, the team drafted an End User License Agreement (EULA).

Figure 2: Data Centers & Legal Territoriality in OWS.EU (from the LISA framework)
In the remaining time of the LISA project, the team plans to focus on the design of a comprehensive legal framework for the Open Web Index, including governance structures and guidelines as well as best practices for its operation. Additionally, the End User License Agreement (EULA) to facilitate the sharing and usage of the index will be finalized and European legislative acts that came into force recently, will be monitored closely and incorporated to project’s plans and policies when necessary.
